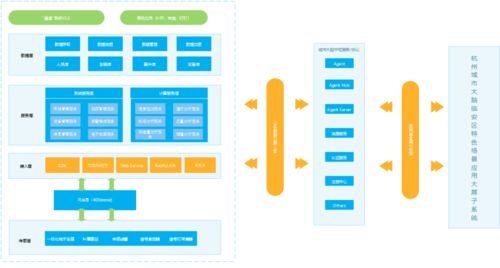
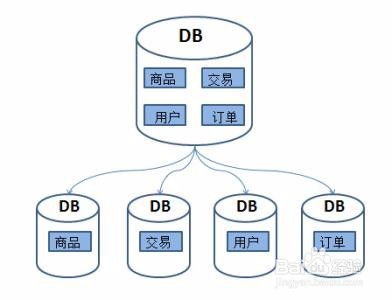
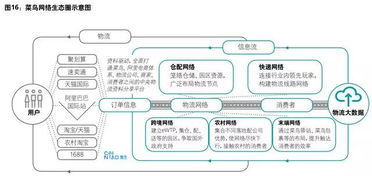
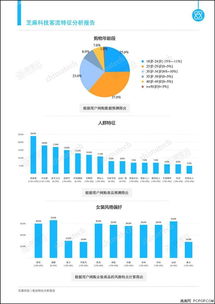
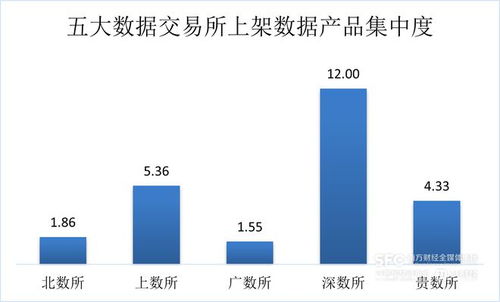
Python典型数据分析流程的理论基础与数据处理服务
数据分析作为现代商业和科研的核心工具,Python凭借其丰富的库生态系统成为主流选择。典型的Python数据分析流程遵循结构化的理论框架,旨在从原始数据中提取洞察,支撑决策。以下是深入理解的纯理论分析流程,结合数据处理服务的应用视角。
一、问题定义与目标设定
数据分析始于业务或研究问题的明确定义。这一阶段需明确分析目标,如预测销售趋势、识别用户行为模式或优化运营效率。理论层面,问题定义涉及确定关键绩效指标(KPIs)和假设检验框架,确保分析方向与整体战略对齐。数据处理服务在此阶段可提供需求咨询,帮助梳理数据需求和可行性。
二、数据收集与集成
数据来源多样化,包括数据库、API、日志文件或外部数据集。Python通过库如Pandas、SQLAlchemy和Requests实现数据抓取和集成。理论重点在于数据质量评估,包括完整性、一致性和时效性。数据处理服务可扩展此环节,提供ETL(提取、转换、加载)管道,自动化数据集成并处理异构数据源。
三、数据清洗与预处理
原始数据常包含噪声、缺失值或异常值,清洗是确保分析可靠性的关键。Python的Pandas和NumPy库支持数据清洗操作,如处理缺失值(通过插补或删除)、去重和标准化。理论层面,需理解统计方法如Z-score检测异常值,或机器学习技术如KNN插补。数据处理服务可提供专业清洗工具,应用规则引擎或AI模型自动化处理,提升效率。
四、探索性数据分析(EDA)
EDA通过可视化和统计摘要揭示数据分布、关系和模式。Python的Matplotlib、Seaborn和Plotly库用于生成图表,如直方图、散点图和热力图。理论核心包括描述性统计(均值、方差等)和相关性分析,帮助形成初步假设。数据处理服务可集成EDA平台,提供交互式仪表盘,加速洞察发现。
五、数据建模与分析
基于EDA结果,应用统计或机器学习模型进行深入分析。Python的Scikit-learn、StatsModels和TensorFlow库支持回归、分类、聚类等算法。理论重点在于模型选择、训练和验证,例如使用交叉验证避免过拟合。数据处理服务可提供模型即服务(MaaS),部署预训练模型或定制化分析流水线,降低技术门槛。
六、结果解释与可视化
模型输出需转化为可理解的洞察,可视化是关键。Python库如Plotly和Bokeh创建动态图表,而理论强调叙事技巧,如用决策树解释特征重要性。数据处理服务可生成自动化报告,结合业务上下文,确保结果 actionable。
七、部署与监控
分析结果集成到生产环境,如通过API或仪表盘。Python的Flask或FastAPI框架支持部署,同时需监控模型性能漂移。理论涉及持续集成和A/B测试框架。数据处理服务提供运维支持,确保分析流程的可持续性和可扩展性。
Python数据分析流程是一个迭代的、理论驱动的循环,从问题到洞察,再反馈到实践。数据处理服务作为支撑,通过专业工具和自动化,提升了流程的效率和可靠性,适用于企业级应用。深入理解这一流程,有助于构建稳健的数据驱动文化。
如若转载,请注明出处:http://www.zhengyingshop.com/product/6.html
更新时间:2026-06-19 12:43:16